Evolution of Data Architectures
Evolution of Data Architectures
The evolution of data architectures has been driven by the increasing volume, variety, and velocity of data in today’s digital age. Over the years, from traditional relational databases to distributed computing, NoSQL databases, cloud computing, and real-time processing, data architectures have continuously evolved to meet the demands of modern data-driven organizations. This write-up aims to provide an overview of the data architecture evolution.
Relational Databases
In the 1980s and 1990s, relational databases and SQL language became the standard storage technology for enterprise applications. One of the main reasons for their popularity was the concept of transactions, which are sequences of operations on a database that adhere to the ACID properties (atomicity, consistency, isolation, and durability).
- Atomicity ensures that all changes made to the database are treated as a single operation, meaning that the transaction is only considered successful if all changes are executed successfully.
- Consistency ensures that the database transitions from one consistent state to another during the transaction.
- Isolation ensures that concurrent operations in the database do not interfere with each other.
- Durability guarantees that once a transaction is successfully completed, its changes are permanently stored, even in the event of a system failure.
The use of relational databases and SQL language in enterprise applications led to the problem of data silos, where each department or business unit stored data in their own proprietary formats. To address this issue, organizations started developing data warehouses to create a unified view of data across different silos.
Data Warehouses
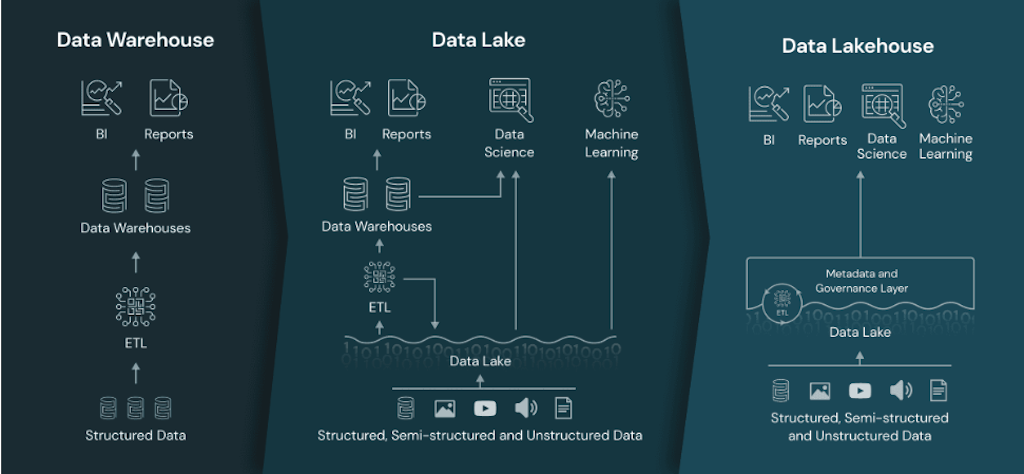
Data warehouse is a central database that stores integrated historical data from multiple sources. Data warehouses provide a unified view of the business with a consistent structure, encompassing all aspects of the organization. Data from the individual business units are extracted, loaded, and transformed to a consistent structure using the ETL pipelines.
Benefits
Data warehouses provide a unified view of high-quality, cleansed, and normalized data from various sources. By having the entire organization’s data in a standardized format, all business units can analyze the results consistently.
Challenges
- They do not utilize in-memory and parallel processing techniques, which restricts their ability to scale vertically.
- They are not equipped to handle the high velocity of big data and lack support for near-real-time data streaming.
- Data warehouses are also not well-suited for storing and querying semi-structured or unstructured data.
- They lack built-in mechanisms for tracking data trustworthiness, focusing primarily on schema rather than lineage and data quality.
- Data warehouses primarily support closed, SQL-based query tools, which limits their compatibility with data science and machine learning tools.
The above limitations gave rise to the more modern cloud-based architectures involving data lakes.
Data Lakes
A data lake is a central repository for storing all types of data, including structured, semi-structured, and unstructured data, in the form of files and blobs. It is called a “data lake” because it is analogous to a real lake that collects water from various sources in real time.
Benefits
Data lakes are scalable and provide support for all forms of data - structured, semi-structured, and unstructured. Data lakes support machine learning and AI use cases.
Challenges
- Traditional data lakes don’t provide ACID compliant transactional support.
- Data lakes use a “schema on read” strategy, which can result in data quality issues.
- Data lakes lack transactional guarantees and require expensive rewrites for updates.
To address the above challenges, organizations often started utilizing data lake + data warehouse architectures resulting in increased costs and data duplication. This led to the rise of data lakehouses.
Data Lakehouses
A data lakehouse is a modern data management architecture that combines the benefits of data lakes and data warehouses. It offers flexibility, cost-efficiency, and scalability like data lakes, while also providing data management capabilities and ACID transactions like data warehouses. This architecture enables businesses to perform business intelligence and machine learning tasks on all types of data.
Delta Lake
A Data lakehouse solution could be implemented using Delta Lake. Delta Lake is an open-table format that combines metadata, caching, and indexing with a data lake storage format. It enables the implementation of lakehouse solutions by providing ACID transactions, scalable metadata handling, a unified process model, full audit history, and support for SQL data manipulation language (DML) statements. Delta Lake can run on existing data lakes and is compatible with various processing engines, including Apache Spark.
Benefits
- Lakehouse architecture eliminates the need for duplicate data storage in a data lake and a data warehouse.
- Data can be sourced from the data lake using the Delta Lake storage format and protocol.
- The performance of sourcing data from the data lake through Delta Lake is comparable to a traditional data warehouse.
Comparison of data warehouse, data lake, and data lakehouse architectures